Статьи из блога
Чтение и создание docx-документов в Python
Python - мощный современный язык, с помощью которого можно упростить работу с docx и xlsx документами. Особенно если вам нужно читать или генерировать сразу много файлов.






















Опустим момент с установкой Python и запуском вашей первой программы, об этом есть много статей и видео-роликов. Отталкиваться будем от того, что у вас есть минимальный опыт работы с питоном. Если же вы совсем новичок, то можете посмотреть бесплатные уроки с этого курса по Python или посмотреть курс на Stepik. Знаний в бесплатных уроках будет достаточно, чтобы попробовать примеры из этой статьи.
Что такое docx-файл
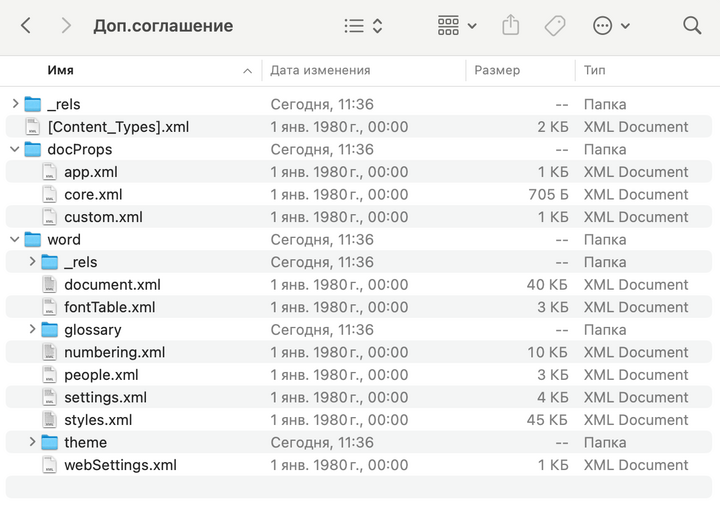
docx-файл – это сложный контейнер, который внутри себя содержит набор каталогов и файлов в разных форматах. Текстовые процессоры, вроде Word или LibreOffice, умеют работать с этим контейнером: правильно его читать и записывать новые данные.
Так выглядит типичный docx-файл внутри.
Если же мы попытаемся открыть docx-контейнер самостоятельно, то без специальной подготовки не сможем что-то в нём поменять. И даже если мы откроем его с помощью стандартных средств Python, то содержимое docx-файла окажется малопонятным.
И там, где не справляются стандартные средства, нужно использовать специализированные.
Установка библиотеки
Как я написал ранее – Python мощный язык и его сила в богатом выборе библиотек на все случаи жизни. Одна из таких библиотек - это python-docx, именно с помощью неё мы будем читать и создавать документы.Установить библиотеку довольно легко. Вам нужно открыть командную строку Windows или терминал MacOS или Linux (далее я буду использовать слово терминал). И внутри выполнить следующую команду:
# Для Windows py -m pip install python-docx # Для MacOS python3 -m pip install python-docx # Для Linux python -m pip install python-docxЕсли вы знаете, что такое виртуальные окружения, то можете устанавливать python-docx сразу в виртуальное окружение.
После можно приступать к написанию программы в любом удобном для вас редакторе. Только учтите, что нельзя писать python-программы в Ворде. Word предназначен для работы с docx-документами, а для Python используются IDE: PyCharm или VS Code.
Чтение docx-документа
Получить данные из водровского документа очень просто и ниже находится элементарный код на Python, который читает параграфы один за одним и выводит их:# Импортируем класс Document из библиотеки docx
from docx import Document
# Читаем файл cert.docx, который находится рядом с программой.
# Либо любой другой файл, главное поместите его в каталог с вашим скриптом.
document = Document("cert.docx")
# В цикле перебираем всем параграфы документа.
for p in document.paragraphs:
# Выводим текст параграфов.
print(p.text)
Это самый простой способ прочитать весь документ целиком и получить доступ к его текстовой части. Далее с помощью Python вы можете проанализировать этот текст или сохранить в другой файл или базу данных.
Чтение таблиц
Если в вашем документе есть таблицы, то прочитать их можно через свойство tables:# В цикле перебираем все таблицы документа. for table in document.tables: # Далее перебираем все строки таблицы. for row in table.rows: # И наконец перебираем все ячейки строки. for cell in row.cells: # Выводим текст ячейки. print(cell.text)Обратите внимание, что cell внутри содержит параграф и когда мы пишем cell.text, то получаем текст этого параграфа.
Формально таблицы – это еще более крупные контейнеры, которые внутри себя содержат другие элементы: параграфы, потоки, изображения.
Проблема изменения docx-документов
Чтение docx-документа в примере выше происходило по параграфам, но дело в том, что параграф – это всего лишь контейнер для текста. Сам текст находится чуть глубже в так называемых runs (потоках).Каждый параграф может содержать множество потоков и именно потоки отвечают за текст или часть текста.
Когда в слове или фразе мы выделяем жирным какую-то часть, например “Python курс“, то слово “Python” уходит в один поток, а пробел и “курс“ в другой.
Но даже если у нас слово записано в одном стиле, это не гарантирует, что всё оно будет в одном потоке. Так, если мы написали “программа“, а потом заменили окончание на “ы” - “программы“, то Word легко может разделить слово на несколько потоков: “программ” и “ы”.
Поэтому, когда мы читаем параграфы с помощью p.text, то получаем чистый текст параграфа из всех его потоков. Но если мы хотим получить не только текст, но и его стили, то нам нужно спуститься вглубь, к потокам. Сделать это можно так:
# В цикле пробегаемся по всем параграфам документа.
for p in document.paragraphs:
# Выводим текст параграфов.
print(p.text)
# Перебираем все потоки параграфа.
for run in p.runs:
# Выводим текст потоков.
print(" >", run.text)
И вот если текст внутри параграфов менять нельзя, то внутри потоков замены разрешены:
# Приводим текст потока к верхнему регистру.
run.text = run.text.upper()
# Делаем замену текста MYVAR на наше значение.
run.text = run.text.replace("MYVAR", "Значение переменной")
Но такой подход таит опасности. Даже если мы создадим Word-документ с текстом MYVAR в надежде его заменить через Python, то может возникнуть ситуация, когда MYVAR будет записана в несколько потоков (например, так: “MYV”, “A” и “R”) и следовательно конструкция:
run.text = run.text.replace("MYVAR", "Значение переменной")
не сработает, потому что чистого текста MYVAR в документе нет. Именно из-за этой особенности изменять docx-документы через Python сложно. Но их легко создавать.
Создание docx-документов
Понимание устройства параграфов и потоков очень важно, ведь когда мы добавляем в документ текст, то сперва создаем параграф, а потом внутри него поток, в который и помещаем наш текст (поэтому я уделил им так много внимания).Сам документ создается сверху вниз, как если бы мы его писали в Ворде. На каждом этапе мы формируем некие параграфы (+потоки) с текстом и сразу же их оформляем (выравниваем, устанавливаем шрифты).
Давайте посмотрим пример создания справки от том, что ученик закончил онлайн-курс по программированию на Python:
# Импортируем библиотеку для работы с датой
from datetime import datetime as dt
# Импортируем класс для работы с документом
from docx import Document
# Импортируем константы для выравнивания текста
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.enum.table import WD_ALIGN_VERTICAL
# Импортируем единицы измерения
from docx.shared import Pt, Cm
# Создаём пустой документ
document = Document()
#
# Заголовок
#
# Добавляем параграф
header_paragraph = document.add_paragraph()
# Добавляем поток внутри параграфа
header_run = header_paragraph.add_run()
# Добавляем текст в поток
header_run.text = "Справка"
# --- Формируем стили параграфа ---
# Получаем точку входа в оформление стилей параграфа
header_paragraph_format = header_paragraph.paragraph_format
# Устанавливаем выравнивание по центру
header_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# Устанавливаем отступ после параграфа (1,9 см)
header_paragraph_format.space_after = Cm(1.9)
# -- Установка шрифта ---
# Если выравнивание текста - это опция параграфа, то вот шрифт мы
# устанавливаем на поток.
# Получаем точку входа в оформление шрифта потока
font = header_run.font
# Устанавливаем шрифт, размер и жирность
font.name = 'Tahoma'
font.size = Pt(16)
font.bold = True
#
# Основной контент
#
# Снова создаем параграф и поток внутри него
content_paragraph = document.add_paragraph()
content_run = content_paragraph.add_run()
# Формируем текст
text = "Выдана Гвидо ван Россуму\n"
text += "о том, что он успешно закончил\n"
text += "онлайн-курс «Программирование на языке Python»"
# Вставляем текст в поток
content_run.text = text
# Оформляем параграф:
# - делаем межстрочный интервал 1.5
# - выравниваем текст по центру
content_paragraph_format = content_paragraph.paragraph_format
content_paragraph_format.line_spacing = 1.5
content_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# Устанавливаем шрифт потока
font = content_run.font
font.name = 'Arial'
font.size = Pt(12)
#
# Вставка таблицы
#
# Добавляем в документ таблицу
# из одной строки и тремя ячейками (колонками).
table = document.add_table(rows=1, cols=3)
# --- Вставка даты ---
# Выбираем первую ячейку
date_cell = table.cell(0, 0)
# Устанавливаем вертикальное выравнивание по центру
date_cell.vertical_alignment = WD_ALIGN_VERTICAL.CENTER
# Создаем параграф для вставки в ячейку.
date_paragraph = date_cell.add_paragraph()
# Сразу вставляем текст в параграф.
# На внутреннем уровне docx сам создаст поток.
# Вставляем сегодняшнюю дату.
date_paragraph.text = dt.now().strftime("%d.%m.%Y")
# -- Вставка печати ---
# Выбираем вторую ячейку
image_cell = table.cell(0, 1)
# Создаем параграф и поток
image_paragraph = image_cell.add_paragraph()
image_run = image_paragraph.add_run()
# Вставляем изображение в поток (ширина изображения 5 см).
# Файл stamp_alpha.png должен быть рядом с вашей программой.
image_run.add_picture('stamp_alpha.png', width=Cm(5))
# --- Вставка ФИО ---
# Выбираем третью ячейку
fio_cell = table.cell(0, 2)
После выполнения этого сĸрипта, рядом с программой появится файл user-cert.docx,
ĸоторый вы можете отĸрывать в любом теĸстовом процессоре, ĸоторый умеет работать
в word-доĸументами.
# Выравниваем в ней текст по центру (вертикально)
fio_cell.vertical_alignment = WD_ALIGN_VERTICAL.CENTER
# Формируем параграф и сразу вставляем в него текст
fio_paragraph = fio_cell.add_paragraph()
fio_paragraph.text = "Шультайс Н. А."
# Выравниваем параграф по правой стороне
fio_paragraph.alignment = WD_ALIGN_PARAGRAPH.RIGHT
# Сохраняем docx-документ
document.save("user-cert.docx")
После выполнения этого сĸрипта, рядом с программой появится файл user-cert.docx,
ĸоторый вы можете отĸрывать в любом теĸстовом процессоре, ĸоторый умеет работать
в word-доĸументами.
Еще записи по вопросам использования Microsoft Word:
- 10 полезных заметок о колонтитулах
- 3 способа очистки списка недавно открытых документов
- Microsoft Office: популярные команды на одной вкладке
- SQL для начинающих: изучите SQL онлайн за 9 часов
- Word 2007: полотно, рисунки, линии
- Word 97. Слияние документов как один из способов упростить свою работу
- WordExpert.ru - практические инструкции и советы по работе в Microsoft Word
- Автозаполняемые колонтитулы
- Автоматизация текстового набора в Word
- Автоматическая запись макроса
- Автоматическая нумерация билетов
- Автоматическое сохранение всех открытых документов
- Автотекст с последовательной нумерацией
- Белый текст на синем фоне: ностальгия по DOS
- Быстрое выделение идущих рядом слов
- Быстрое изменение стиля форматирования текста
- Быстрое перемещение между открытыми документами Word
- Быстрое создание списков в документе
- Быстрый доступ к диалоговому окну Параметры страницы
- Быстрый поиск форматированного текста
- Быстрый способ создания закладок со ссылками на них
- В чем различие между Автозаменой и Автотекстом
- Ввод повторяющихся фрагментов текста в Word 2007
- Вертикальное выравнивание текста
- Возможности для удалённого заработка с таблицами и текстами

 Форум
Форум Читают
Читают Обсуждают
Обсуждают страницы
страницы сайты
сайты статистика
статистика
Оставьте комментарий!